
Git 原理应知应会

初学编程时,Git 算是最令人心有余悸的 Boss 了,毕竟相比于写出 Bug 这种常见事情,把自己/别人代码弄丢这种事更为可怕。
本文只介绍 Git 原理中最为硬核的部分,如果想把所有原理都探究明白,内容多到可以写本书。因此,本文只试图解答:
- Git 是怎么存储内容的?存到哪里了?
- 工作区,暂存区,版本库,各种教程里这仨名词一看就晕,能说人话吗?
- git reset 来,git reset 去,感觉啥都能 reset,我到底在干啥?
- Git 快在哪里?大神都说 Git 好用,怎么还这么难学?
Let’s go!
一、Git 简介
首先回顾一下 Git 是什么,Git 是一个分布式版本控制系统(Distributed Version Control System - DVCS)。由 Linux 之父 Linus Torvalds 用两周时间写出了第一个版本。经过十多年的发展,Git 的内部设计基本没有变化。
它与先前流行的版本控制系统 SVN 相比,区别在于,除了中央仓库,还有本地仓库。中央仓库仅负责同步团队代码,其它如查看历史,提交代码等操作可以在成员的本地仓库中进行。除此之外,SVN 存储的是版本间的文件差异,Git 存储的则是每一个版本的快照,后面我们将详细说明。
二、Git 文件系统
我们对于 Git 的使用,都是在使用命令,例如 git add,git commit 等,它们都属于 Git 的高层命令。
通过 git help -a 查看所有的 Git 命令:

实际上,Git 有一百多个命令,其中底层命令被设计为 Unix 风格,由脚本调用,并不常用。我们平时所使用的高层命令设计的更为友好(可以理解为是被高度封装过的现成工具)。因此,想要了解 Git 原理就必须从底层命令入手。

每当执行 git init 时,Git 便会创建一个 .git 目录,几乎 Git 所储存,操作的所有内容都在这个目录下(如果想拷贝一个 Git 仓库,拷贝这个目录即可)。了解 Git 原理也可以称为了解这个这个目录各部分是做什么的。

(图中是我的一个小项目的 .git 目录)
- 指针 (HEAD, FETCH_HEAD, ORIG_HEAD)
- 对象
- objects/(所有的对象,包括blob, tree, commit)
- refs/ (所有的引用)
- local branch
- remote branch
- tag
- index (索引)
- config (设置)
接下来我们来重点介绍一下 objects 和 refs 两个部分。
1. objects

(刚初始化的项目,objects 目录下只有两个空文件夹)
首先看一下最基本的部分,objects 目录,Git 所存储的数据都在这里。我们来看看 Git 到底是怎么存储内容的吧。
前面提到了 Git 存储的是快照,这实际上说的是 SHA-1 哈希值。
Git 为每份内容生成一个文件,取得其 SHA-1 哈希值,用哈希值的前两个字符为名称创建子目录,用剩下 38 个字符为文件命名 (保存至子目录下)。
听起来有点绕口,我们可以动手操作实验一下,通过底层命令 hash-object 可以计算内容的 SHA-1 值:

字符串 hello git 的哈希结果是 8d0e41234f24b6da002d962a26c2495ea16a425f
把这段字符串保存在一个文件中再计算 SHA-1:

得到了一样的哈希值。
改变一下文件的文本内容,哈希值则发生了改变:

至此,我们已经知道:
- Git 由文件内容计算其哈希值
- 哈希值相同则文件内容相同(即使我们将一个文件拷贝到不同目录下,Git 也仅存储一份内容)
现在我们把 hello.txt 文件提交:

再看一下 objects 目录。

发现多了三个文件夹!其中 8d 文件夹和子文件名加起来(8d0e4123...)正好是字符串 hello git 的哈希结果。而 10 文件夹则是本次 commit 的哈希值。
除了 hash-object 命令之外,还有一个好用的底层命令 cat-file,它可以将数据内容取回,传入 -p 参数可以让该命令输出数据内容的类型。我们拿 commit 的哈希值试一试:

我们得到了 commit 对象,其中包含了本次提交的时间,commit message,提交者信息,以及一个类型为 tree 的哈希值 07ed5a7。对其取值查看,发现了第三个哈希对象,类型为 blob,其哈希值为 hello.txt 内容的哈希值。
三个哈希对象之间的关系:

在此,我们已经知道了三种 Git 基本对象:
- Blob 对象:对单个文件的压缩存储
- Tree 对象:对文件目录树的存储
- Commit 对象:对 tree 对象的包装,带有其它提交信息
因此仓库中的一个常规项目结构,在 .git 中会存储为右图所示的结构:

现在我们再把 bye.txt 也提交了。可以发现新的 commit 哈希对象中还包含了 parent 信息,其值为上一个 commit 的哈希值。
Git history 中的各个 commit 其实是一个单向链表的结构,通过 parent 关联父节点。

其中每个 commit 中都包含了当时仓库的目录结构与文件内容。这便是达成版本管理的基础。
2. refs
refs 目录存储了所有的引用文件。

引用文件的内容也都是 40 位的 SHA-1 值。先看一下 master 是什么:
cat .git/refs/heads/master
哈希值为 38779e1ee3e4959e21e599ad0974a2c915613d9e,就是第二次提交 commit 的哈希值。我们可以猜测,branch 其实就是 commit 的引用。为了验证一下这个想法,我们新建一个分支试试:

可以发现,refs 目录中多了一个与新分支同名的文件,且其哈希值依然为第二次提交 commit 的哈希值。所以我们的猜想没错。
但是当我们新建 new-branch 分支时,Git 是怎么知道最后一次提交的 SHA-1 值呢?答案就是 HEAD 文件。HEAD 文件是一个指向你当前所在分支的引用标识符。也就是我们每次查找 log 时看到的 HEAD 标记:

介绍到这里,我们可以发现Git 中的引用是非常廉价的,开新的 branch 和 tag 都只是多了一个引用文件,而有些中央式版本控制系统开分支时会复制一份内容,非常耗费资源。
分支是一种移动的引用。而标签则是静止的引用。.git/refs 目录下的 tags 目录就是保存标签信息的地方,标签同样也是 commit 对象的引用,只是它永远指向同一个 commit,不会变化。
最后一种引用类型是 remote reference 远程引用,我们每次执行将提交 push 到远端后,.git/refs/remotes/ 目录下就会记录此次与远端通信的最后一个 commit 的哈希值。
与 Git 的引用文件强相关的高层命令是 git reset [--soft | --mixed | --hard | --merge | --keep] [-q] [<commit>],虽然这个命令后面可以加很多参数,但实际上它们所操作的都是 .git/refs/heads 目录下当前分支对应的引用文件。
三、Git 暂存区
工作区,暂存区,版本库,这三个名词是我一开始看各种 Git 教程时最脑阔疼的东西,每次都要小心辨认,再心里默念一遍才分的清楚。其中工作区和版本库还好理解,暂存区 是最为懵逼的一个概念。
所以来看看 Git 暂存区到底是什么,为什么需要这个东西呢。
在 .git 目录下中有一个 index 文件它与暂存区的概念相关,我们动手实验看看它是干啥的。就着前面的实验,我们继续操作一下,改一下 hello.txt 的内容,然后执行 git checkout 撤销对这个文件的修改:

撤销后工作区已经没有文件改动了,发现 .git/index文件的时间戳是 17:02:00。

再通过 git status 看一下工作区状态,发现 .git/index 文件的时间戳没有变化。
我们用 Linux 命令 touch 改一下 hello.txt 的时间戳再看看:

发现虽然文件没有变化,.git/index 文件的时间戳却发生了改变。
这是因为
git status命令查看工作区状态时,先根据 .git/index 文件中记录的时间戳,长度等信息判断工作区文件是否改变。如果时间戳变了,说明文件有可能发生改变,Git 需要读取文件,与原始文件进行对比,去判断它是否发生变化。如果没有改变,则将文件新的时间戳记录到 .git/index 文件中。因为判断文件是否更改,使用时间戳、文件长度等信息进行比较要比通过文件内容比较要快的多,所以 Git 这样的实现方式可以让工作区状态扫描更快速的执行,这也是 Git 高效的因素之一。
.git/index 文件实际上是一个包含文件索引的目录树,就是所谓的暂存区,它记录了文件的名称,时间戳,长度等信息,但并不储存文件,文件内容依然位于 .git/objects 中。.git/index 中的索引建立了文件和对象库中对象实体之间的对应。
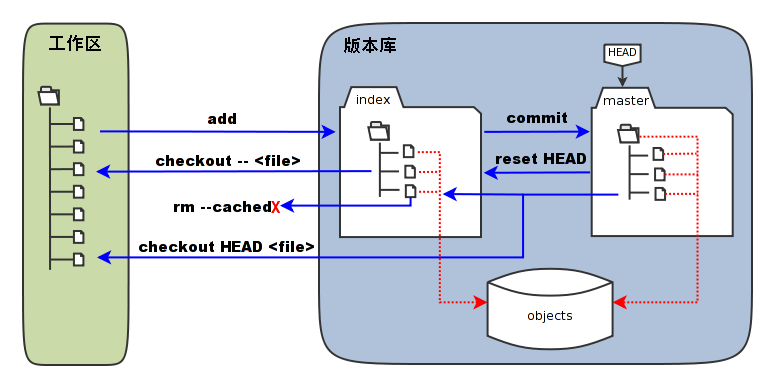
图中版本库中的 index 区域就是暂存区,可以看到 index 区域与 master 区域其实都是对 objects 中存储的文件内容的索引。与先前了解到的一致,游标形状的 HEAD 是一个指向当前所在分支的标识符。
图中还列出了 Git 命令是如何影响工作区与暂存区的。值得注意的是 git reset HEAD 命令。
git reset 有两种使用方法:
git reset [--soft | --mixed | --hard | --merge | --keep] [-q] [<commit>]git reset [-q] [<commit>] [--] <paths>
在前面我们了解到第一种使用方法实际上是改变了引用文件。 git reset 的第二种使用方法并不会改变引用,它会用已经 commit 到版本库的文件替换掉暂存区中的文件。因此,git reset HEAD <paths> 就是取消之前执行 git commit <paths> 时所改变的暂存区。
四、Git 的痛点
粗浅地了解了以上原理之后,对于 Git 的痛点也可以窥知一二。
Git 的诞生经历和 JavaScript 有些相似,都是短时间内打造的兵器,其设计思路一开始就是很粗糙的,甚至有些不合理反人类的地方。(但是 JavaScript 还有 ECMAScript 一年一年的修补,Git 却没啥指望改进了……)
最明显的一个痛点是,一个 Git 命令身兼数职的情况非常多(git rebase,git reset,git checkout 是重灾区),这也是造成新手入门时每天一脸懵逼的一个主要原因。
Git 本身的设计理念是非常清晰明确的,如果可以重新设计的话,希望指令可以与其设计思路统一,指令分为四类:
- 操作当前指针
- 操作分支
- 操作版本
- 操作工作环境
有一篇论文《Purposes, Concepts, Misfits, and a Redesign of Git》专门分析 Git 的设计问题。最后设计了一款新工具叫 Gitless。
除了这一点之外,由于 Git 存储的是文件快照,如果项目需要频繁修改大文件的话很容易造成存储库的膨胀,这一点虽然有解决方案,但不可否认依然是其痛点之一。
五、最后
除了以上介绍到的内容,git rebase,git reflog,git checkout,git cherry-pick 也都是值得探究的命令。