
字符编码
作为编程知识基础中的基础,有必要消化整理输出一次。
本文主要介绍了字符编码的几个重要基础概念,从 ASCII 到 Unicode 再到 Emoji 与 JavaScript 字符处理的一些坑。
基础概念
由于计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字。计算机中,字节(byte) 是一个 8bit 的储存单元,一个字节能表示的最大的整数就是 255(二进制的11111111 = 十进制255),如果要表示更大的整数,就必须用更多的字节。
字符集
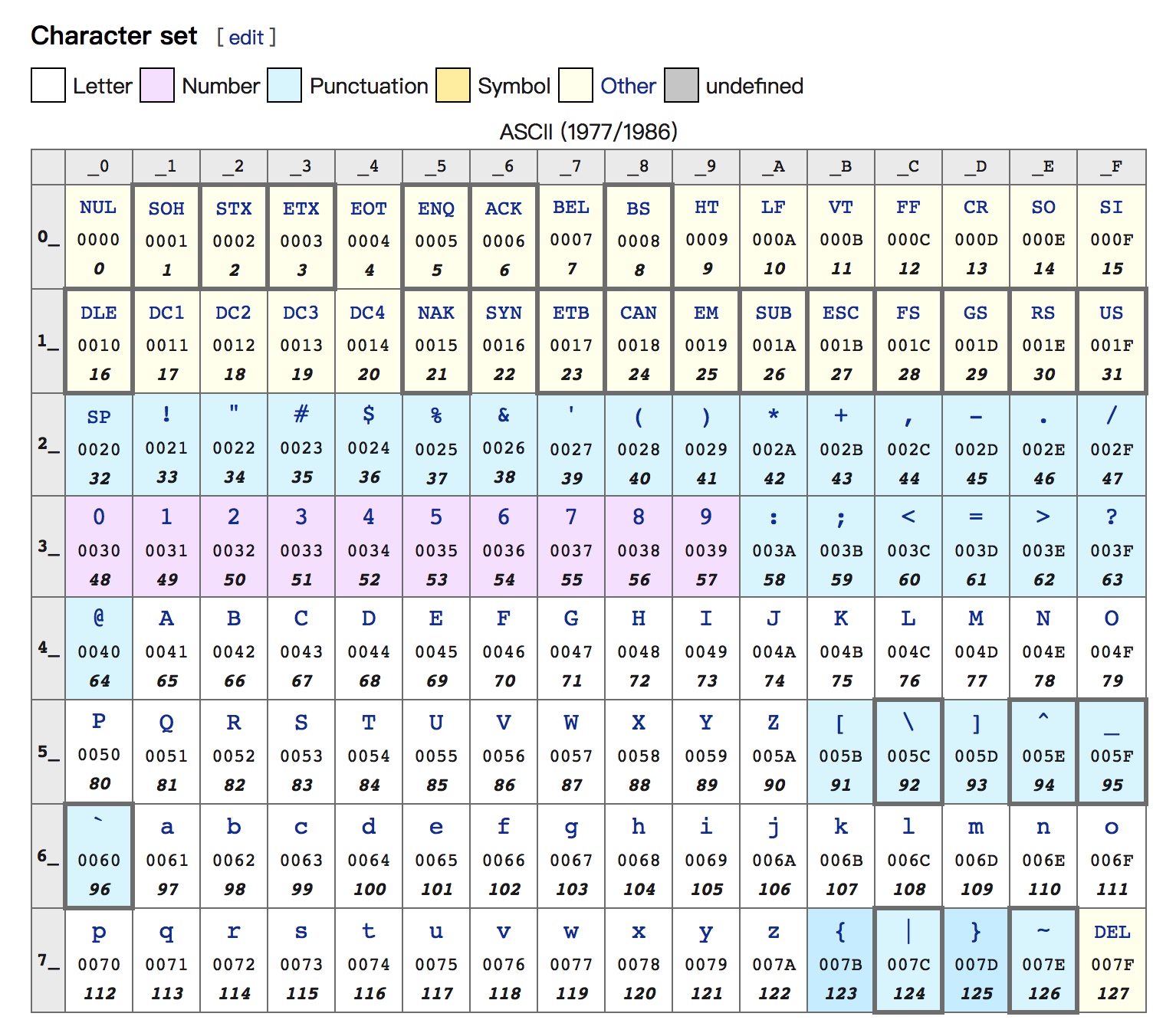
字符是文字与符号的总称,它是一个信息单位。字符集就是字符的集合。ASCII码(American Standard Code for Information Interchange)就是一个字符集,这个集合中只有数字,英文字母和一些符号共 127 个字符。如果我们想处理中文、日文文本,仅通过 ASCII码 就做不到了。在历史中由于眼光的局限性,出现了一些仅能处理部分字符的字符集,无法通用。
字符编码
字符编码规定了字符集和实际存储的二进制数值之间的转换关系。一般来说,每个字符集都有其对应的字符编码方式(有的字符集有一个对应字符编码,有的则有多个)。像 ASCII 与 GB18030 都仅有一种编码实现,因此既可以作为字符集的名字,也可以用来指代它们的字符编码。
通过以上概念的介绍不难窥探在字符编码的历史中存在以下痛点:
- 字符集不够通用,总有覆盖不到的字符
- 新的字符集难以向下兼容老的
- 覆盖更多字符的字符集,难以避免需要更多字节,如果我们的文本仅通过
ASCII就能处理的话,使用占用字节更多的字符集在储存和传输都不划算
这些问题都由 Unicode 及其字符编码一起打包解决了。
Unicode
Unicode 是一个字符集,旨于涵盖所有国家语言中可能出现的符号与文字,是目前绝大多数程序使用的字符编码。
Unicode的诞生也不是一蹴而就,也有历史过程。
历史进程
(这段不是用来凑数的,这几个英文简写后面还会一直出现,知道了历史更方便记忆分辨)
ISO 与 IEC 分别推出了 Unicode 与 UCS(Universal Multiple-Octet Coded Character Set) 。后来(只过了一年),两者进行整合,到了 Unicode2.0 时代,Unicode 的编码和 UCS 的编码都完全一致。
USC 这个名字也并未从此消失在历史中。UCS 标准有自己的格式,如UCS-2,UCS-4等等 而 Unicode 也有自己的不同编码实现,如UTF-8,UTF-16,UTF-32等等。
关于 Unicode 自己
码点 code point 是指在 Unicode 字符集中字符的值,根据 Unicode 标准,是前缀为 U+ 的十六进制数字。
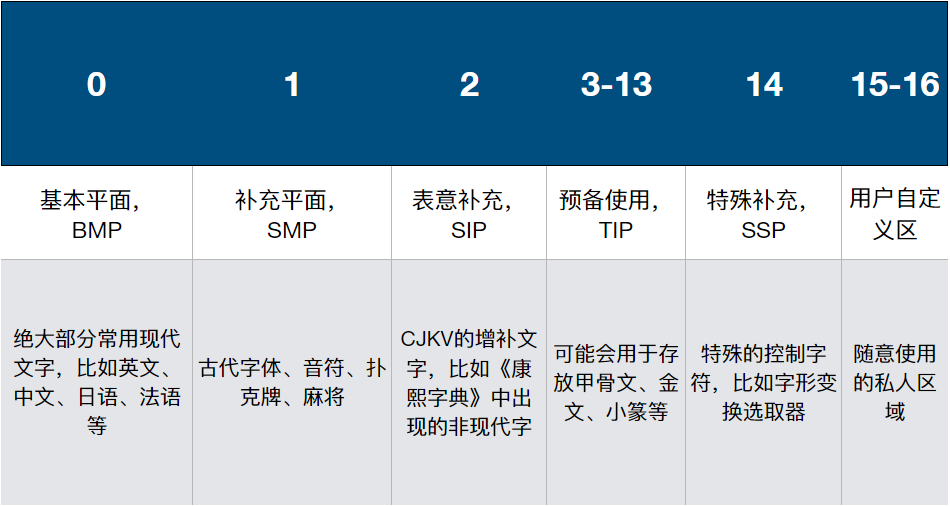
Unicode 字符分为 17 组平面(plane),每个平面拥有 2^16 (65,536) 个码点。每一个码点都可以用 16 进制 xy0000 到 xyFFFF 来表示,这里的 xy 是表示一个 16 进制的值,从 00 到 10。目前我们常用字符大多都在 BMP 基本平面中。
字节序与 BOM
在了解 Unicode 的字符编码之前,还需要了解一个关于 字节序 的知识。
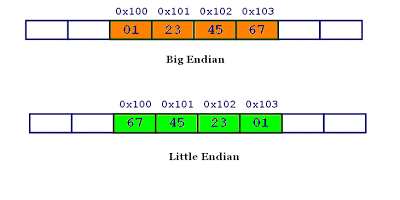
计算机硬件有两种储存数据的方式:大端字节序(big endian)和小端字节序(little endian)。
- 大端字节序:高位字节在前,低位字节在后
- 小端字节序:低位字节在前,高位字节在后
因此,0x1234567 的大端字节序和小端字节序的写法如下图:
字节序的存在主要是因为计算机电路先处理低位字节,因为计算都是从低位开始的。但是,人类还是习惯读写大端字节序。所以,除了计算机的内部处理,其他的场合几乎都是大端字节序,比如网络传输和文件储存。
Unicode 规范中推荐的标记字节顺序的方法是 BOM(Byte Order Mark)。有一个叫做”零宽度非换行空格(ZERO WIDTH NO-BREAK SPACE)”的字符,它的编码是 FEFF。而 FFFE 在 UCS 中是不存在的字符,所以不应该出现在实际传输中。Unicode 规范中定义每个文件的最前面加入这个零宽度非换行空格字符,如果一个文本文件的头两个字节是 FE FF,就表示该文件采用大端方式;如果头两个字节是FF FE,就表示该文件采用小端方式。
需要清楚的是,不是所有的东西都有字节序,而且字符序是以单字节为单位的顺序问题。
前面提到 Unicode 有多种字符编码实现方式,我们主要介绍 UTF-8 与 UCS-2。
UTF-8
UTF-8 作为最常见的 Unicode 实现方式,解决了前面提到的字符编码几大痛点。
UTF-8 编码是变长编码,用 1 到 6 个字节编码,完全兼容 ASCII 码,对于 ASCII 涵盖的那些字符,单字节实现,其余大多数为三字节实现。对于以英文为主的文本非常友好,最节省存储空间。缺点主要在于
UTF-8 编码通过多个字节组合的方式来显示,这是计算机处理UTF-8 的机制,它是无字节序之分的。
UTF 家族还有 UTF-16(双字节) 与 UTF-32(四字节) 实现,两者都有字节序问题,前者更适合汉字编码但不支持单字节的 ASCII,后者由于浪费储存空间很不常见,HTML5 中明确规定禁止使用 UTF-32 编码。
UCS-2
JavaScript 设计之初,还没有出现 UTF-16,因此采用的是 USC-2 编码。前面提到 Unicode 的编码和 UCS 的编码都完全一致。UCS-2 是一种定长的编码方式,用两位字节来表示一位码位。
UTF-16 可看成是 UCS-2 的父集。在没有辅助平面字符(surrogate code points)前,UTF-16 与 UCS-2 所指的是同一的意思。但当引入辅助平面字符后,就称为 UTF-16 了。现在若有软件声称自己支持 UCS-2 编码,那其实是暗指它不能支持在 UTF-16 中超过 2 字节的字集。对于小于 0x10000 的 UCS 码,UTF-16 编码就等于 UCS 码。
因此在 ES6 之前,JavaScript 对于超出 USC-2 的字符无法正确处理,会导致字符长度、正则匹配判断错误,使用字符串的 charCodeAt() 与 fromCharCode() 也无法正确识别字符与码点。
ES6 新增了 codePointAt() 与 fromCodePoint() 方法以正确处理 32 位的 UTF-16 字符之外的字符。
Emoji
|
|
看起来就很刺激。
随着 Emoji 表情的流行,在开发中就不得不了解、考虑 Emoji 字符了。否则最简单的 textarea 文本字数限制需求都难以正常完成。
随着政治正确的发展,Emoji 现在是非常多元化了:

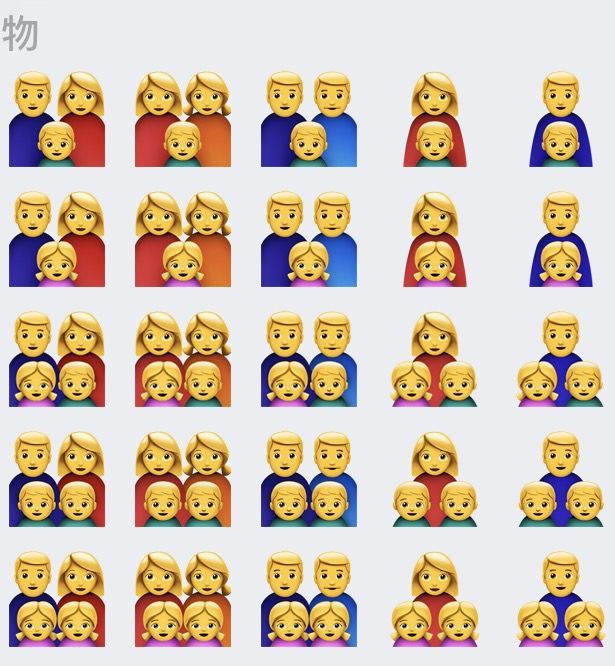
肤色,职业,性别,取向,家庭组成都十分多元,基本覆盖了所有情况。
其实在原先的基础 Emoji 字符上拓展出这些多元化字符并不难,通过码点组合就能实现。
肤色修饰符: 🏻 🏼 🏽 🏾 🏿
通过这几个肤色修饰符拼接到原有表情上,就可以实现肤色多元化:

通过 零宽字符 ZWJ(U+200D) 可以实现 family emoji,U+200D 相当于是一个连接符,连接家庭成员 emoji:
|
|
因此,遇到文本有可能含有 Emoji 的情况中,需将 Emoji 字符正则匹配出来,单独进行计算。
参考
字符编码相关知识还有很多,本文仅介绍最近工作中所涉及的部分。更完善更准确的内容建议参考英文维基。