
阅读《高性能JavaScript》(下)

5.字符串和正则表达式
字符串构建原理
str += 'one' + 'two'
这行代码运行时会经历四个步骤:
1.在内存中创建一个临时字符串
2.链接后的字符串 ‘onetwo’ 被赋值给该临时字符串
3.临时字符串与 str 当前值连接
4.结果赋给 str
过程中产生的临时字符串造成了较大的性能开销,应当避免在字符串构建过程中创建临时字符串:
str = str + 'one' + 'two'
由于IE之外的浏览器会给表达式左侧字符串分配更多内存,然后把第二个字符串拷贝到最左侧字符串的末尾,因此如果在循环中,基础字符串位于最左端,就可以避免重复拷贝一个逐渐变大的基础字符串。
除此之外,使用数组项合并的方法(Array.prototype.join)比其它字符串连接方法更慢,String.prototype.concat 也比简单的 + 和 +=更慢,构建大字符串时会造成灾难性的性能问题。
在此也拓展一个vajoy大大提到的知识点, 字符串方法是如何调用的?
字符串(String)类型属于基本类型,它不是对象,那我们是怎么调用它的 concat、substring 等字符串属性方法呢?
在 JavaScript 的世界中万物皆对象
|
|
其实在每次调用 s1 的属性方法时,后台都会默默地先执行 s1=new String('some text') ,从而让我们可以顺着原型链调用到String对象的属性(比如第二行调用了 substring)。
在调用完毕后,后台会再默默销毁掉这个先前创建的包装对象,因此在第三行代码执行完毕之后, s1即被销毁,最后 alert 的结果是 undefined
“引用类型与基本包装类型的主要区别就是对象的生存期。使用new操作符创建的引用类型的实例,在执行流离开当前作用域之前都一直保存在内存中。而自动创建的基本包装类型的对象,则只存在于一行代码的执行瞬间,然后立即被销毁。这意味着我们不能在运行时为基本类型值添加属性和方法。” ——《高程三》
正则表达式优化
本节内容最重要的是理解 回溯 :
回溯法采用试错的思想,它尝试分步的去解决一个问题。
在分步解决问题的过程中,当它通过尝试发现现有的分步答案不能得到有效的正确的解答的时候,它将取消上一步甚至是上几步的计算,再通过其它的可能的分步解答再次尝试寻找问题的答案。
回溯法通常用最简单的递归方法来实现,在反复重复上述的步骤后可能出现两种情况:
1.找到一个可能存在的正确的答案
2.在尝试了所有可能的分步方法后宣告该问题没有答案
在最坏的情况下,回溯法会导致一次复杂度为指数时间的计算。
回溯是正则表达式匹配过程中的基础部分,使用不当也会造成非常大的计算消耗。提高效率的方法:
加快匹配失败的过程:正则表达式慢的原因通常是匹配失败的过程慢:
123var str = 'eABC21323AB213',r1 = /\bAB/.test(str), //匹配失败的过程较长r2 = /^AB/.test(str); //匹配失败的过程很短减少分支条件,具体化量词:
123var str = 'cat 1990'; //需匹配:19XX年出生的猫或蝙蝠var r1 = /(cat|bat)\s\d{4}/.test(str); //不推荐var r1 = /[bc]at\s19\d{2}/.test(str); //推荐,减少分支,具体化量词使用非捕获组,在不需要反向引用的时候
只捕获感兴趣的文本以减少后处理:如果需要引用匹配的一部分,应该先捕获那些片段,再用反向引用来处理
拆开复杂的表达式:避免在一个正则表达式中处理太多任务。复杂的搜索问题需要条件逻辑,拆分成两个或多个正则表达式更容易解决,通常也会更高效
6.快速响应的用户界面
有一次和一位月饼厂的安卓开发聊天,她说她最近跟合作的前端沟通很费劲,她一直想弄明白浏览器UI线程是不是单线程,可是那个前端也不明白这个概念,由此引出了对一些前端开发人员业务知识薄弱的吐槽。听的时候我也没法做任何反应,我也并不清楚这个概念 = =
好在这一章节就围绕浏览器的UI线程展开的,依然是干货很多让人“知其所以然”。
浏览器UI线程
大多数浏览器让一个单线程共用于执行 JavaScript 和更新用户界面,每个时刻只能执行其中一种操作,这意味着当 JavaScript 代码正在执行时用户界面无法响应输入,反之亦然。
好像是很容易理解的,但还是深入了解一下 wikipedia 中 线程 的定义:
线程(英语:thread)是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。
再看一下什么是 进程:
进程(英语:process),是计算机中已运行程序的实体。程序本身只是指令、数据及其组织形式的描述,进程才是程序(那些指令和数据)的真正运行实例。
用户下达运行程序的命令后,就会产生进程。同一程序可产生多个进程(一对多关系),以允许同时有多位用户运行同一程序,却不会相冲突。
进程需要一些资源才能完成工作,如CPU使用时间、内存、文件以及I/O设备,且为依序逐一进行,也就是每个CPU核心任何时间内仅能运行一项进程。
然而常规浏览器并不会只有一个线程在运作,主要线程可归类为:

基础知识补到这里,半路出家的程序员心好累。
UI线程的工作基于一个简单的队列系统 ,任务会保存到队列中直到线程空闲,一旦空闲队列中的下一个任务就被重新提取出来并运行。先看一个简单的交互例子来理解UI线程的队列系统:
|
|
按钮上绑定了一个点击事件,点击后会调用 handleClick() 函数。
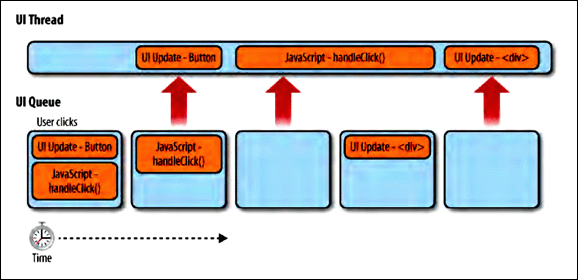
按钮被点击,触发UI线程创建两个任务并添加到队列中。
- 更新按钮UI
- 执行 JavaScript 即执行
handleClick()函数段代码
执行 JavaScript 过程中创建了新的 div 元素并附加在 body 后,又触发了一次UI更新
大多数浏览器在 JavaScript 运行时会停止吧新任务加入 UI 线程的队列中,因此如果用户试图在任务运行期间与页面交互,不仅没有即时的 UI 更新,可能连 UI 更新任务都不会加入到队列中。
当脚本执行时,UI 不随用户交互而更新,执行时间段内用户交互行为所引发的 JavaScript 任务会被加入队列中,并在最初的 JavaScript 任务完成后一次执行。而这段时间里由交互行为引发的 UI 更新会被自动跳过。因此在一个脚本运行期间点击一个按钮,将无法看到它被按下的样式,尽管它的 onclick 事件处理器会被执行。
使用定时器进行优化
单个 JavaScript 操作花费的总时间不应该超过100毫秒。否则用户会感到与界面失去联系。
有一些复杂的任务无法在100毫秒内执行完毕则需要停止 JavaScript 的执行,让出线程控制权使得 UI 可以更新。因此我们需要使用定时器进行优化。
创建一个定时器会造成 UI 线程暂停,也会重置所有相关的浏览器限制,包括长时间运行脚本定时器和调用栈。这使得定时器成为长时间运行 JavaScript 代码理想的跨浏览器解决方案。
|
|
需要注意 setTimeout() 和 setInterval() 函数中的第二个参数表示任务何时被添加到 UI 队列,而不是一定会在这段时间后执行。定时器代码只有在创建它的函数执行完成之后才有可能被执行。如果调用setTimeout()的函数又调用了其他任务,耗时超过定时器延时,定时器代码将立即被执行,它与主调函数之间没有可察觉的延迟。
同时需要注意的是定时器的精度问题: 定时器延迟通常并不精准,不可用于测量实际时间。所以延迟的最小值建议为25毫秒,以免加上误差延时实际上变得更小,不够进行UI刷新。
我以前还想过用定时器来 console.log 打印出来运行耗费时间来进行优化测试之类的,这样看来还是 too naive ,所以该怎么记录代码的运行时间?
|
|
我们也可以利用类似思路,把需要长时间运行的脚本切割成小任务来执行:
|
|
克隆需执行的任务数组来进行操作,每次取一项并从数组中移除这项(array.shift()),如果此时程序所耗费时间少于50毫秒,那就见缝插针地继续指向任务项,否则就先停止执行代码,25毫秒后继续。
定时器很好用,但是滥用也同样会导致性能问题。
在上面定时器的例子中,我想到了另一个通过定时器来实现的优化点:函数节流 throttele 与 函数防抖 debounce。
Throttle and Debounce
Throttle 和 Debounce 函数都可以限定函数的执行时间点,在
window.onresize事件中:
使用throttle(action, time)可以让action在time时间内一定执行且只执行一次;
使用debounce(action, time)函数可以让action在resize停止time时间之后执行。
函数节流与防抖都是避免了连续触发事件而导致浏览器崩溃,简单的封装实现:
|
|
即事件连续触发时,throttle(action, time) 中的 action 会每隔 time 时间就触发一次。
|
|
即事件连续触发时,debounce(action, time) 中的 action 并不会立即执行;当第二次触发 window.onresize 事件时,如果两次事件发生的间隔小于 time,则仍然不执行 action,只有两次间隔大于 time 才会执行 action。
更多内容可以阅读 《浅谈 Underscore.js 中 .throttle 和 .debounce 的差异》,文中用电梯策略来讲解节流与防抖的区别,以及在 Underscore.js 中的实现,非常值得一看。
7.Ajax
这一节内容比较杂,并且一些内容和优化建议现在并不实用了,大概参考一下吧。
GET 与 POST 的区别
GET 请求是幂等的,经 GET 请求的数据会被缓存起来,对于少量数据而言 GET 请求往服务器只发送一个数据包,POST 请求发送两个数据包,一个装载头信息一个装载 POST 正文。只有当请求的 URL 加上参数的长度接近或超过2048个字符时才使用 POST 获取数据。
这是书中给的信息,然而是不准确的。
实际上,URL不存在参数上限的问题,HTTP协议规范没有对URL长度进行限制。这个限制是特定的浏览器及服务器对它的限制。,区别主要在语义上,POST 请求并不是明文因而相对更安全,以及书中提到的数据包数量的区别。
更多详细内容可参考 《浅谈HTTP中Get与Post的区别》
8.编程实践
避免双重求值
- 避免以
new Function()的形式来创建函数 - 避免用
setTimeout/setInterval执行字符串,可改为传入函数
- 避免以
使用 Object/Array 直接量可以加快运行并且也节省了代码
- 用速度最快的部分(位操作,原生 JavaScript)
后面两章没有太多可参考的新内容,都比较过时,就不记录了~ done!