
阅读《高性能JavaScript》(上)

这篇只包含前四章节。
1.加载与执行
浏览器使用单一进程来处理用户界面UI刷新和JavaScript脚本执行。脚本执行过程中会阻塞页面渲染。
减少脚本执行对性能影响的方法:
- 把所有
<script>标签尽可能放到<body>标签底部。 - 合并脚本,减少HTTP请求带来的额外性能开销。
- 无阻塞下载执行JavaScript脚本:
<script>的defer属性可以使脚本下载后先不执行,老版本浏览器不支持- 书中未提到的 HTML5
async属性可以使脚本异步加载执行 - 使用XHR对象动态加载脚本

这部分的知识是刚接触JavaScript时就看过的,IBM开发者的文章介绍的很详尽。
2.数据存取
本章主要讲通过改变数据的存取位置来提高读写性能,其中又详细讲解了作用域链,原型链的工作原理,干货不少。
首先要了解,一共有四种基本的数据存取位置:字面量,本地(局部)变量,数组元素,对象成员。其中字面量和局部变量的存取很快,数组元素和对象成员相对较慢,尤其是在老版本浏览器。
作用域与作用域链
每一个JavaScript函数都可以表示为一个对象,Function对象既有可编程访问的属性,又有仅供JavaScript引擎存取的内部属性,其中一个内部属性是[[scope]]。
作用域链是[[scope]]所包含的函数被创建的作用域中对象的集合,作用域链决定了哪些数据可被函数访问以及查找数据的顺序。
- 执行函数时会创建一个
execution context 执行上下文,它是一个内部对象,函数每次执行时对应的执行上下文都是不一样的。函数执行完毕,执行上下文就被销毁。 执行上下文被创建时,它的作用域链就初始为执行函数的[[scope]]属性中的对象。这些值按顺序被复制到作用域链中,这一过程完成,即创建好了“活动对象”。- 活动对象是函数运行时的变量对象,包含所有局部变量,命名参数集合以及
this。然后活动对象会被推入作用域链的最前端。
在函数执行过程中,每遇到一个变量都会在搜索其作用域链,从头部(即活动对象)搜索直到找到标识符,正是这个搜索过程影响了性能。
在执行环境的作用域链中,一个标识符所在的位置越深,读写速度越慢。所以读写局部变量最快,全局变量最慢。全局变量总是在作用域链的最末端。
经验:如果一个跨作用域的值在函数中被引用一次以上,那就把它存储在局部变量里。
两种改变作用域链的情况
有两个语句可以在执行时临时改变作用域链:with语句与try-catch中的catch子句。
with语句 有性能问题,应避免使用。它是创建了一个包含参数制定对象属性的新对象,并把它推入作用域链最前端,使得局部变量位置变深读写变慢。
try-catch的catch子句在执行中是把捕捉到的错误对象推入作用域链首位,也会造成同上的性能问题。解决办法是,在子句中把错误委托给一个函数来处理:
|
|
闭包,作用域与内存
有了先前理论的了解,我们就可以理解一下与闭包有关的性能问题。
|
|
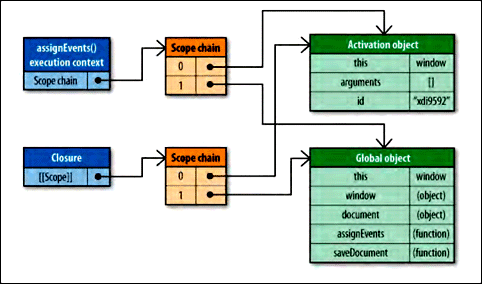
闭包函数在执行时,它的作用域链与属性 [[scope]] 中所引用的两个相同的作用域链对象一起被初始化,作用域链首位是闭包函数的活动对象,然后是外部函数的活动对象,最后是全局对象。闭包函数执行时用到的id和saveDocument在作用域链第一位之后,这就是使用闭包需要关注的性能点。
对象成员,原型与原型链
前文提到的,访问对象成员的速度慢于访问字面量和局部变量 ,原因是什么?
脚本引擎在读取对象属性时,也会按顺序检索。具体可参考这篇博文。
3.DOM编程 生来缓慢,我很抱歉
JS引擎和DOM引擎是分开的,所以脚本中对DOM的访问非常耗费性能。最坏的情况是在循环中访问或者修改DOM,此时应该把DOM缓存在局部变量中。
HTML集合
需要区分一下HTML集合和数组,使用jQuery选择器或者DOM节点引用的,返回的都是HTML集合:
document.getElementById('one')$('#one')
之前在lodash文档里也发现Collection和Array是分开的栏目,当时没当回事儿,现在想想其实是我压根就没有HTML集合的概念,HTML集合并不是数组,也没有数组可用的方法(etc.slice()),只是提供了length属性并且可通过数字索引来访问集合中的元素。
HTML集合是低效之源 ,集合是实时性的,一直保持着与文档的连接,任何操作和访问都会重复DOM操作。在相同的内容和数量下,遍历一个数组的速度明显快于遍历一个HTML集合。因此也更不应该遍历或循环HTML集合。如果非要进行这种操作的话,建议:
- 不要在循环的条件控制语句中读取 length 属性(这个无论是集合还是数组都通用)
把集合转为数组再操作
123456function toArray (coll) {for (var i = 0, a = [], len = coll.length; i<len; i++) {a[i] = coll[i]}return a}访问集合时使用局部变量,把length缓存在循环外部,把需要多次读取的元素存在局部变量中
querySelectorAll()
关于选择器API,建议使用 document.querySelectorAll() 的原生DOM方法来获取元素列表。
与getElementById等api不同,querySelectorAll() 仅返回一个 NodeList 而非HTML集合,因此这些返回的节点集不会对应实时的文档结构,在遍历节点时可以比较放心地使用该方法。
重绘与重排
此博文:《网页性能管理详解》中也详细介绍了关于浏览器重排与重绘相关的知识。
调用一下方法时会 强制浏览器刷新队列并触发重排 :
offsetTop/offsetLeft/offsetWidth/offsetHeight
scrollTop/scrollLeft/scrollWidth/scrollHeight
clientTop/clientLeft/clientWidth/clientHeight
getComputedStyle()
因此如果需要多次查询布局信息如offsetTop时,应把其缓存起来。
减少重排的方法有三种,使元素脱离文档流(display:none),在文档之外创建并更新一个文档片段并附加到原始列表(document.createDocumentFragment),克隆节点(cloneNode)。
比较推荐的是第二个方案,所产生的DOM遍历和重排次数最少:
|
|
事件委托
每绑定一个事件处理器都是有代价的,要么加重了页面负担,要么增加了运行期的执行时间。所以我们需要使用事件委托来减少事件处理器的数量,而不是给每个元素都绑上事件处理器。
关于事件委托也是一个坑,先参考一下stackoverflow: What is DOM Event delegation,后续再参考高程研究一波。
4.算法和流程控制
也是很涨姿势的一章。
循环语句
ECMA-262 标准中一共有四种循环类型,for循环,while循环,do-while循环,for-in循环。前三种循环类型性能所差无几,只有for-in比其它几种明显要慢,除了明确需要迭代一个属性数量未知的对象,否则应避免使用for-in循环 。
改善循环性能的切入点有两种:
减少迭代工作量
减少对象成员及数组项的查找次数:如上一章所提到的,把数组的length存到局部变量中
123for (var i=0, len=items.length; i < len; i++) {process(items[i])}采用倒序循环:在每次循环中减少了一次查找属性,减少了控制条件中的一次数值比较
123for (var i=items.length;i--; ) {process(items[i])}
减少迭代次数
- 一个涨姿势的概念 达夫设备(Duff’s Device) 适合迭代次数超过1000的场景(虽然现在应该不会再引用这种方法,但是switch-case的思想可以借鉴)
除了上述四种基本的循环类型,数组后续还引入了基于函数的迭代方法forEach(),但是在所有情况下,基于循环的迭代比基于函数的迭代快8倍。
条件语句
if-else与switch比较之下,条件数量较小时使用if-else,较多时使用switch
优化if-else的方法一是确保最可能出现的条件放在首位,二是把if-else组织成嵌套的if-else语句。
递归
这里更涨姿势了,不过描述的内容和场景目前基本没遇到过,不会把那么大的数据量放在前端处理,用Node写服务器端的话可能会遇到。先记住这几个结论吧:
浏览器的调用栈大小限制了递归算法在 JavaScript 中的应用,栈溢出错误会导致其它代码中断运行。
如果遇到栈溢出错误,可以把方法改成迭代算法。